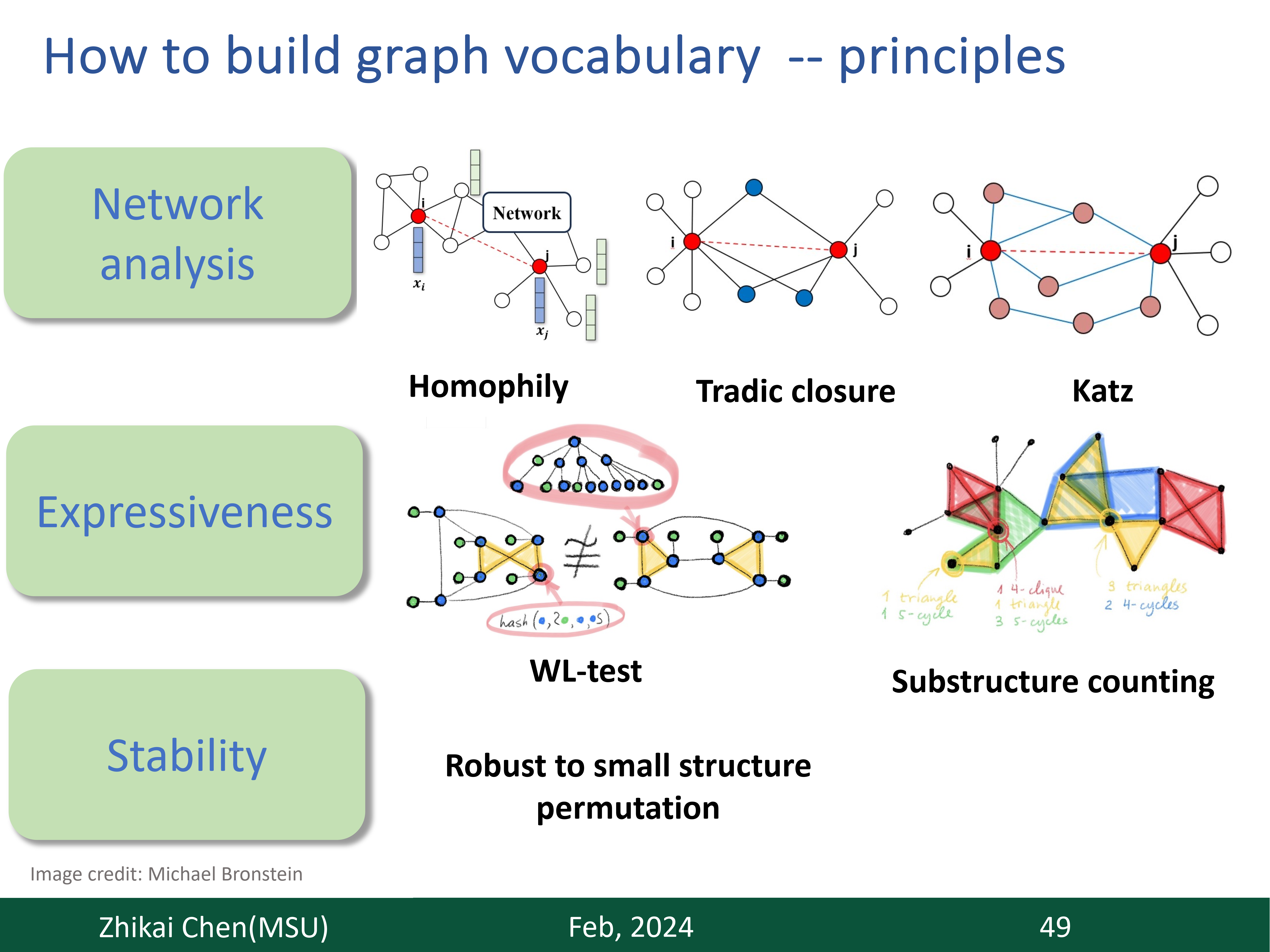
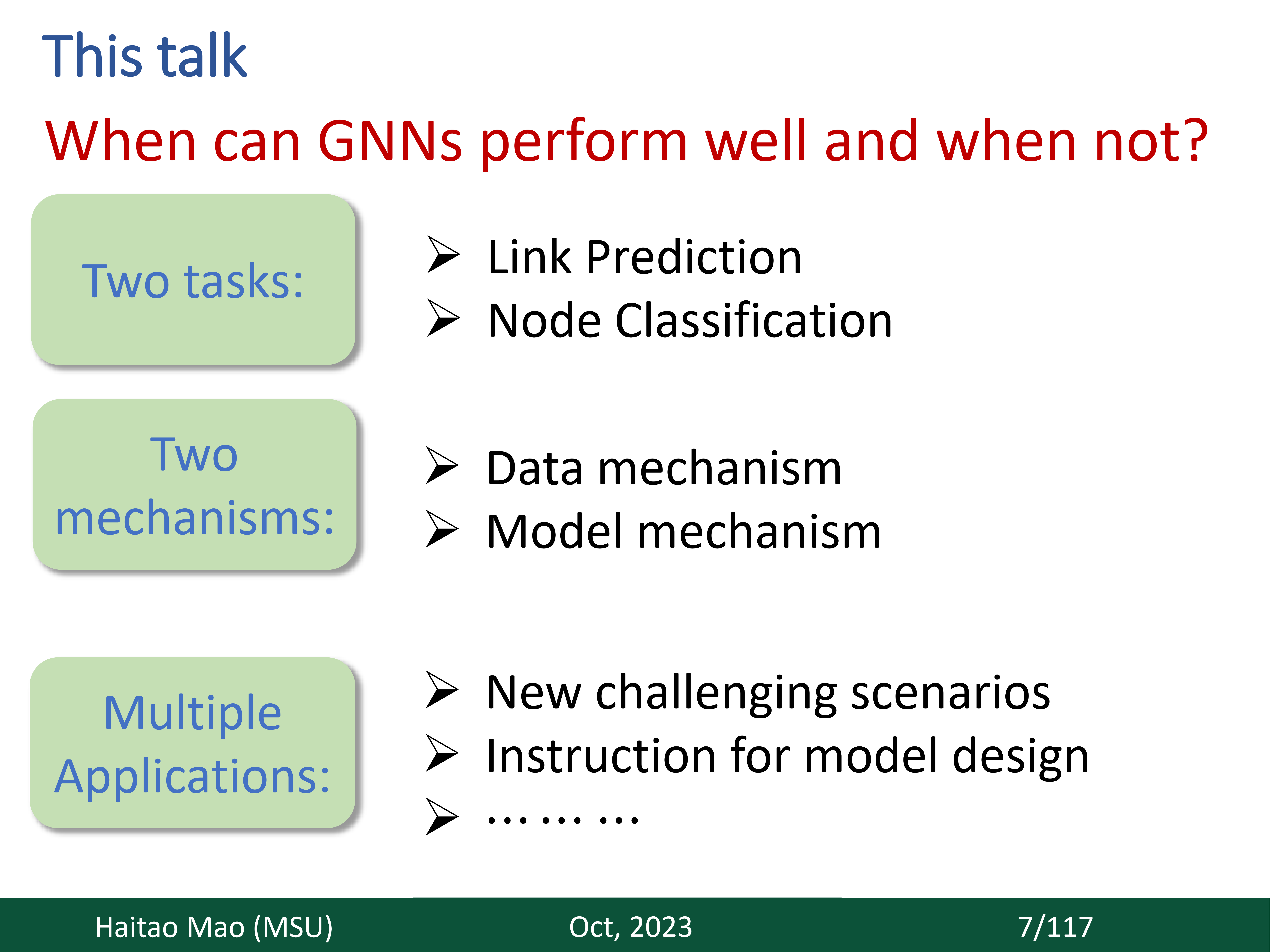
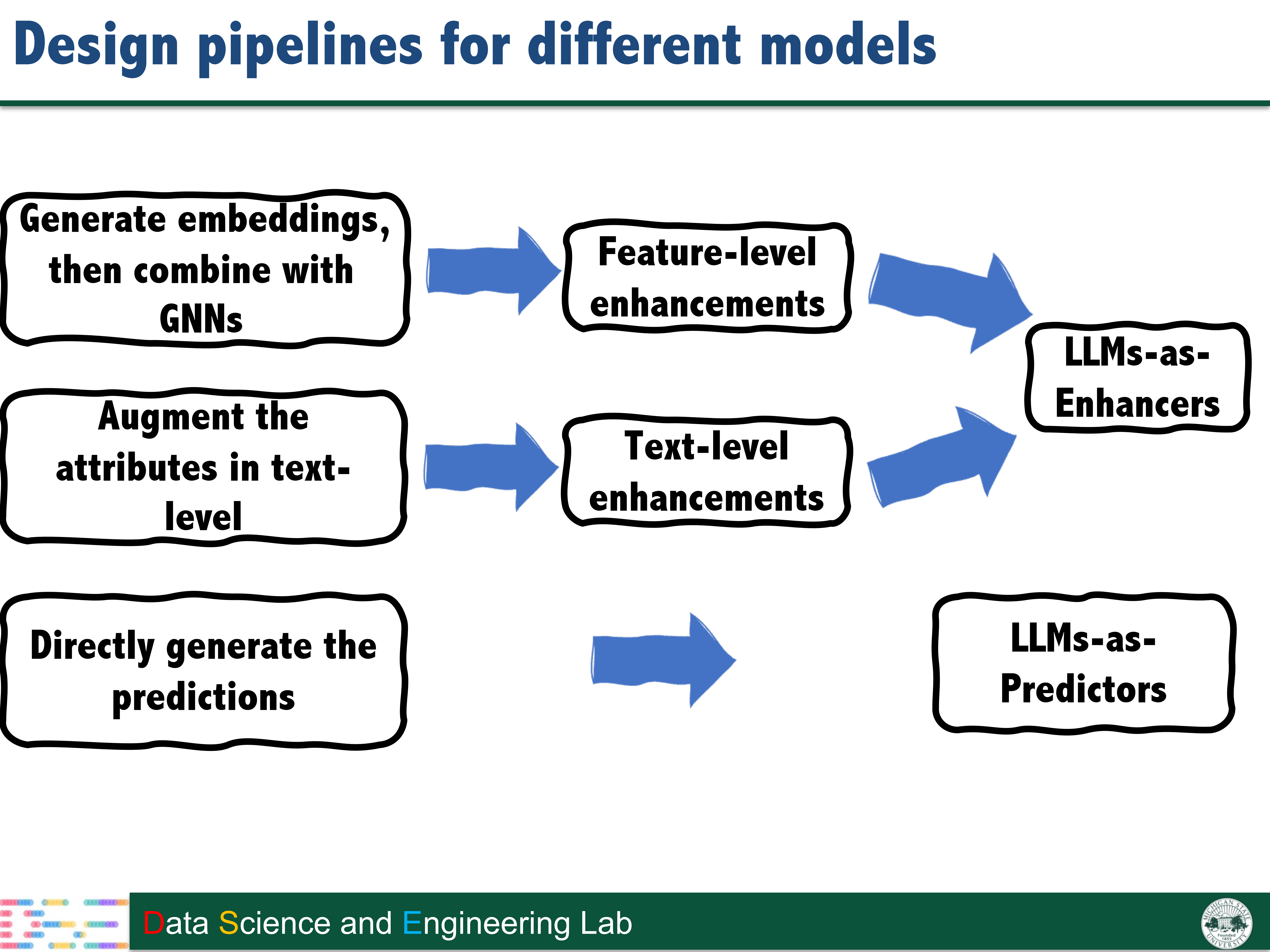
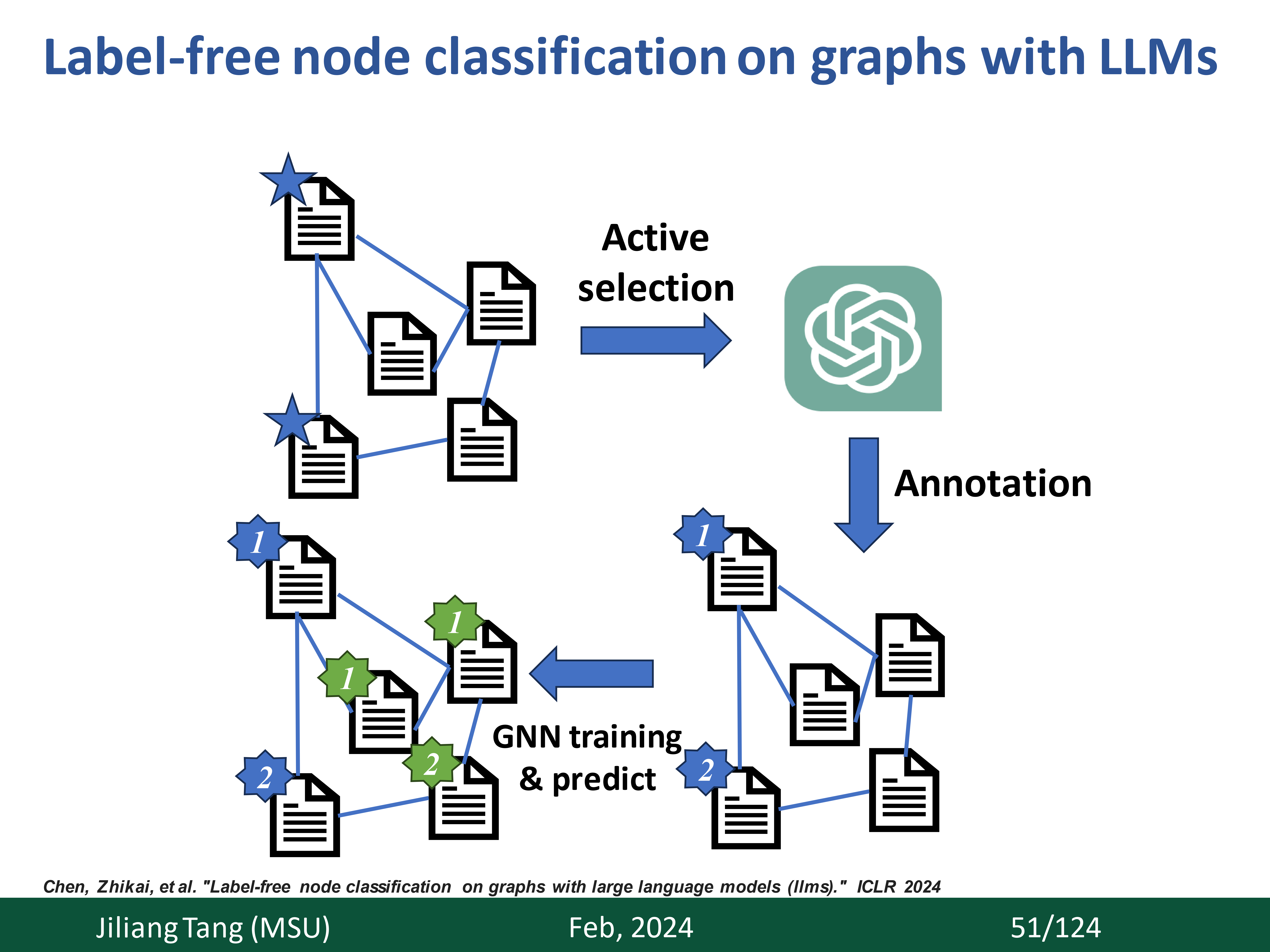
Greetings! We are a tiny research group from the Data Science and Engineering (DSE) Laboratory at Michigan State University. We typically focus on the Graph Foundation Models (GFM). Our perspectives are as follows: (1) LLM can be one choice for building GFM, but not yet. (2) GFM requires the guidance from theoretical principles. This is exciting as it connects the advanced progress from theory to unbeatable empirical success (Check details here). (3) There is an initial spark for Neural scaling law on graphs. We need more high-quality data, a better model backbone, and a better pre-training task design toward scaling. (4) the most important thing for GFM is the correct application scenario. Beyond traditional graph topics in the data mining domain, we are also interested in the potential of the utilization of GFM in other domains. Check more details on our current progress including papers, talks, open-source repository, and reading list.
We sincerely thank the people below for their guidance and collaboration in our research work.
Advisory: Neil Shah, Tong Zhao, Yao Ma, Wei Jin, Michael Galkin, Jian Tang, Michael Bronstein, Xavier Bresson, Bryan Hooi,Haiyang Zhang,Xiafeng Tang,Chen Luo.
Students: Harry Shomer, Juanhui Li, Guangliang Liu,Jianan Zhao, Xiaoxin He, Qian Huang, Xinyu Yuan, Zhaocheng Zhu.